

Update: This is a re-post of an older blog post of mine. Originally it was posted on my personal blog where it has ~40 comments and >35'000 views over the last years. I'm deprecating my personal blog in favor of this 200OK blog.
In this short tutorial, I’m going to show you how to scrape a website with the 3rd party html-parsing module BeautifulSoup in a practical example. We will search the wonderful translation engine dict.cc, which holds the key to over 700k translations from English to German and vice versa. Note that BeautifulSoup is licensed just like Python while dict.cc allows for external searching.
First, place BeautifulSoup.py in your modules directory. Alternatively, if you just want to do a quick test, put in the same directory where you will be writing your program. Then start your favourite text editor/Python IDE(for quick prototyping like we are about to do, I highly recommend a combination of IDLE and VIM) and begin coding. In this tutorial we won’t be doing any design; we won’t even encapsulate in a class. How to do that, later on, is up to your needs.
What we will do:
- go to dict.cc
- enter a search word into the webform
- submit the form
- read the result
- parse the html code
- save all translations
- print them
All required code is embedded in this post. At the bottom, you will find the complete code in one snippet.
Now, let the magic begin. Those are the required imports.
import urllib
import urllib2
import string
import sys
from BeautifulSoup import BeautifulSoup
urllib and urllib2 are both modules offering the possibility to read data from various URLs; they will be needed to open the connection and retrieve the website. BeautifulSoup is, as mentioned, a html parser.
Since we are going to fetch our data from a website, we have to behave like a browser. That’s why will be needing to fake a user agent. For our program, I chose to push the webstatistics a little in favour of Firefox and Solaris.
user_agent = 'Mozilla/5 (Solaris 10) Gecko'
headers = { 'User-Agent' : user_agent }
Now let’s take a look at the code of dict.cc. We need to know how the form is constructed if we want to query it.
...
<form style="margin:0px" action="http://www.dict.cc/" method="get">
<table>
<tr>
<td>
<input id="sinp" maxlength="100" name="s" size="25" type="text" />
style="padding:2px;width:340px" value="">
...</td>
</tr>
</table>
</form>
...
The relevant parts are action, method and the name inside the
input tag. The action is the web application that will get called when
the form is submitted. The method shows us how we need to encode the
data for the form while the name is our query variable.
values = {'s' : sys.argv[1] }
data = urllib.urlencode(values)
request = urllib2.Request("http://www.dict.cc/", data, headers)
response = urllib2.urlopen(request)
Here the data get’s encapsulated in a
GET
request and packed into the form. Notice that values is a dictionary
which makes handling more complex forms a charm. The form gets
submitted by urlopen() – i.e. we virtually pressed the
“Search”-button. See how easy it is? These are only a couple lines of
code, but we already have searched on dict.cc for a completely
arbitrary word from the command line. The response has also been
retrieved. All that is left, is to extract the relevant information.
the_page = response.read()
pool = BeautifulSoup(the_page)
The response is read and saved into regular html code. This code
could now be analyzed via regular string.find() or re.findall()
methods, but this implies hard-coding in reference to a lot of the
underlying logic of the page. Besides, it would require a lot reverse
engineering of the positional parameters, setting up several
potentially recursive methods. This would ultimately produce ugly(i.e.
not very pythonic) code. Lucky for us, there already is a full fledged
html parser which allows us to ask just about any generic question.
Let’s take a look at the resulting html code, first. If you are not
yet familar with the tool that can be seen in the screenshot; I’m
using Firefox with the
Firebug addon.
This one is very helpful if you ever need to debug a website.
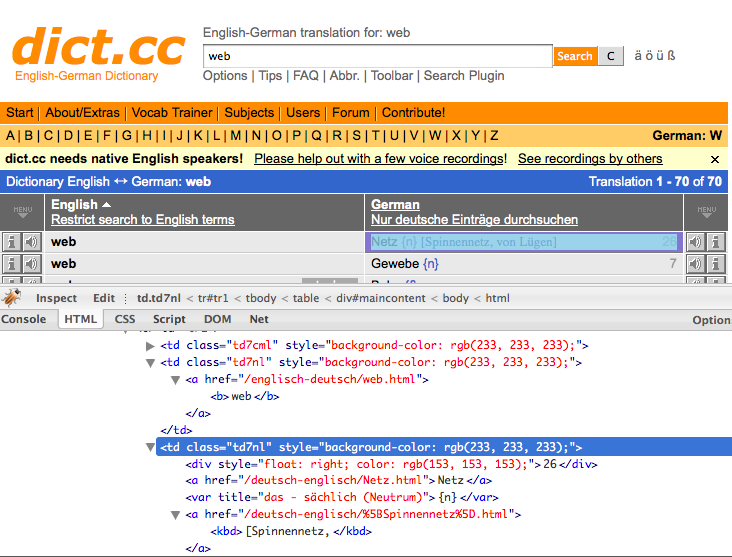
Let me show an excerpt of the code.
<table>..
<td class="td7nl" style="background-color: rgb(233, 233, 233);">
<a href="/englisch-deutsch/web.html">
<b>web</b>
</a>
</td>
<td class="td7nl" ... /td>
</table>..
The results are displayed in a table. The two interesting columns
share the class td7nl. The most efficient way would seem to just sweep
all the data from inside the cells of these two columns. Fortunately
for us, BeautifulSoup implemented just that feature.
results = pool.findAll('td', attrs={'class' : 'td7nl'})
source = ''
translations = []
for result in results:
word = ''
for tmp in result.findAll(text=True):
word = word + " " + unicode(tmp).encode("utf-8")
if source == '':
source = word
else:
translations.append((source, word))
for translation in translations:
print "%s => %s" % (translation[0], translation[1])
results will be a BeautifulSoup.ResultSet. Each member of the tuple is
the HTML code of one column of the class td7nl. Notice that you can
access each element like you would expect in a tuple.
result.findAll(text=True) will return each embedded textual element of
the table. All we have to do is merge the different tags together.
source and word are temporary variables that will hold one translation
in each iteration. Each translation will be saved as a pair(list)
inside the translations tuple.
Finally we iterate over the found translations and write them to the screen.
$ python webscraping_demo.py
kinky {adj} => 9 kraus [Haar]
kinky {adj} => nappy {adj} [Am.]
kinky {adj} => 6 kraus [Haar]
kinky {adj} => crinkly {adj}
kinky {adj} => kraus
kinky {adj} => curly {adj}
kinky {adj} => kraus
kinky {adj} => frizzily {adv}
In a regular application those results would need a little lexing, of course. The most important thing, however, is that we just wrote a translation wrapper onto a web application – in only 28 lines of code.
Complete code
import urllib
import urllib2
import string
import sys
from BeautifulSoup import BeautifulSoup
user_agent = 'Mozilla/5 (Solaris 10) Gecko'
headers = { 'User-Agent' : user_agent }
values = {'s' : sys.argv[1] }
data = urllib.urlencode(values)
request = urllib2.Request("http://www.dict.cc/", data, headers)
response = urllib2.urlopen(request)
the_page = response.read()
pool = BeautifulSoup(the_page)
results = pool.findAll('td', attrs={'class' : 'td7nl'})
source = ''
translations = []
for result in results:
word = ''
for tmp in result.findAll(text=True):
word = word + " " + unicode(tmp).encode("utf-8")
if source == '':
source = word
else:
translations.append((source, word))
for translation in translations:
print "%s => %s" % (translation[0], translation[1])
All that is left is for me to recommend the BeautifulSoup documentation. What we did here really didn’t cover what this module is capable of.
I wish you all the best.
