

Testing deserves and requires it's own spot in the development plan. It is understandable to only plan ahead sparingly, because many developers dislike testing. They tend to test gently, subconsciously knowing where the code will break and avoiding the weak spots. However, with the proper training and setup, you can find your bugs now and not later.
Finding bugs is somewhat like fishing with a net. At 200ok, we use fine, small nets (unit tests) to catch small fish, and big, coarse nets (integration tests) to catch the killer sharks.
We encourage you to start testing as soon as you have code.
Our mantra is: Test early. Test often. Test Automatically.
Writing End-to-End-Tests will improve the quality of your application for some simple reasons:
- Before you’ve written any code, you know how you want it to behave
- Test software against a specification
- Evaluate a program’s correctness after a change
- Yields examples for other developers
It's proven that using Test-Driven-Development (TDD) practices, your code will have better design and less bugs. For example, Microsoft found in a study across multiple teams and products that TDD teams produce code with a 60-90% better defect density
- TDD Teams also take about 15-35% longer to complete projects
- The trade-off is significantly reduced post-release maintenance costs, since code quality is so much better
Having said that, writing good End-to-End-Tests (aka. Integration- or Feature-Tests) is not trivial and therefore not favored by some programmers. One reason is that compared to other tests, they are rather unwieldy. More important though, when written without the proper guideline, they will often be brittle.
End-to-End-Tests, as the name suggest, have to integrate the whole system, and thus there is probably not much we can do about unwieldy, apart from having a nice DSL to make them more concise and thus more readable.
However, even if they are rather slow, they are comparatively fast compared to do integration testing by hand. Why? For every new feature developed, there is an exponential amount of work to be done for regression testing. Let's compare the effort of manually testing an application over time (as more features are developed) with automated Integration-Tests.
With automated tests, you leave the hard, repetitive and boring work to the machine. Those kinds of jobs, machines are very good at - whereas humans get bored and make mistakes on repetitive tasks.
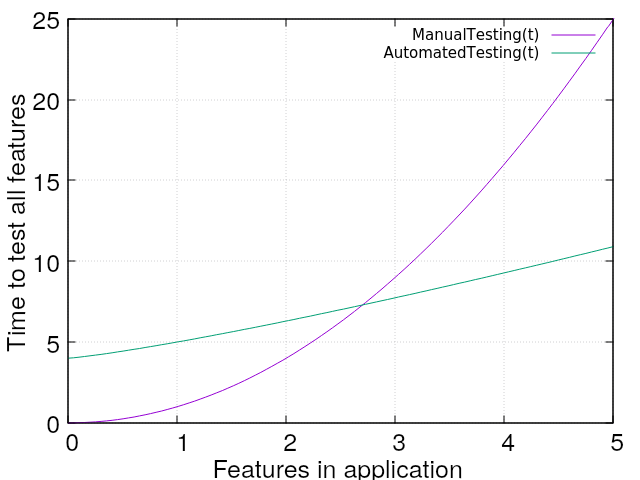
As you can see, there definitively is an initial overhead of writing integration tests compared to testing by hand. However, as soon as some more features are developed, the automated test suite gains quickly and overtakes the manual testing process.
Note: Consider the math of the graph above as a rule of thumb. The actual effort for both automated tests and manual tests are very different for different kinds of programs. Therefore this is nothing more than a rough sketch, not an actual scientifically proven fact for every scenario.
So, yes, compared to other kinds of automated tests, Integration-Tests are unwieldy and slow. However, compared to the only other solution (manual testing), they are very fast!
Having spoken about speed, we should speak about brittleness.
Brittle (typical) End-to-End-Tests
A typical End-To-End-Test visits a page in the application, simulates some user interactions, like filling in a form and clicking a button or a link, and then asserts certain facts about the resulting page.
Over the years, we found that End-To-End-Tests often break, when there is work done in the markup or even in the design. The feature might still work perfectly fine, but the tests did use some implementation detail like a name or a CSS class that isn't being used anymore - and voilà: the tests fails. This is unacceptable. It costs time and resources to fix these tests even though the code works and there is no regression. Such a test doesn't fullfill its duty as a warning system for regressions, it is a false positive. And a warning system that has too many false alarms is of no use. With too many false alarms no one will duck and cover when the real alarm sounds. So let's fix those false positives.
The following example uses Rspec (with Capybara). This is a setup in a typical Rails app, but the overall strategy to solve the discussed issues can be applied in any technology stack. Capybara is very expressive, so it'll be easy for you to transpose the knowledge to a different stack.
Let's start with a typical -- a brittle -- test.
describe 'Login' do
it 'logs the user in' do
visit '/'
fill_in 'user_email', with: 'foo@bar.com'
fill_in 'user_password', with: 'secret'
find('.login').click
expect(page).to have_selector('.dashboard')
end
end
The test goes to the root page, fills in the login form, submits it
and then asserts the existence of an element with a specific class on
the resulting page. To do that, it needs to reference elements in the
page and that's OK. However, the test is tightly coupled to
implementation details, like: The email field is named user_email,
the password field is named user_password, the submit button has the
class login, and the resulting page has an element with the class
dashboard. That makes it a brittle test!
The origin for all these names and classes are beyond the scope of an Integration-Test. The names of the form are likely coupled with the model and for the CSS classes it's likely that some CSS styles are attached to these classes for layouting purposes.
Having established that the origin of the names are beyond the scope of the test means that these names might change at any time. This leads to a situation where the test will fail and give a false positive. The feature still works, but the test fails because the feature has been implemented in a different way.
To solve this issue, it's good practice to introduce a CSS namespace
for testing. Let's prefix the existing names with test-. In our test,
we used two CSS classes login and dashboard, so we introduce
test-login and test-dashboard. Let us call these classes
buoys.
Introducing Buoys
In our markup, we add the buoy test-login to the submit button and
the buoy test-dashboard to the element with the class dashboard on
the resulting page. In our test, we will replace the existing
references to CSS classes with our new namespaced classes.
For form fields it's more tricky. As the function fill_in only
takes an id (or name), but we still want to use our buoys, we will
have to add one level of indirection. First we have to find the
element in question and then we query it for its name to use that as
the first argument to fill_in.
input = find(:css, '.test_user_email')
fill_in input[:name], with: 'foo@bar.com'
We do this likewise for all form fields. By doing so, we gain multiple benefits: Through namespacing, we avoid naming conflicts. Using a dedicated namespace in CSS for writing tests makes the references from tests to markup and CSS explicit in both directions. Before, we could read a test and see that it referenced elements in the markup via a CSS selector or other means. But there was no way to read the markup and see that an element is of significance to a test.
Now, if we're refactoring the markup and we see a class like
test-login on a button, we can assume that at least one test will use that class
to identify the login button, and if it gets lost during refactoring,
we expect that test to fail. Hence, it raises awareness that at least
one test will fail if removed. You don't get that out of regular CSS
classes, because naturally you think they are for attaching styles - not
tests. To a lesser degree of certainty, it additionally indicates that
an element in the markup is covered by tests.
This ultimately allows us to define certain rules, which we apply when we work with these classes.
The three rules for working with buoys
A buoy is a CSS class that starts with test-. In that way
buoys make up a namespace within CSS.
-
From your tests (or specs), only refer to buoys, and give them meaningful names. Don't use other CSS classes, nor other means of identifying elements in the markup.
-
Never attach any styles to buoys. buoys are for attaching tests, not styles.
-
When doing front-end work, like a redesign or changing markup, be careful to not lose any buoys. Make a list of the buoys you remove and put them back in when you're done.
These rules will make our tests resilient to redesigns. This means that our tests will stay intact while we change the markup or design. They will prevent you from getting false positives from your test suite where tests fail, while your feature still is working perfectly fine.
Happy testing!
